Clover: Closed-Loop Verifiable Code Generation
The use of large language models for code generation is a rapidly growing trend in software development. However, without effective methods for ensuring the correctness of generated code, this trend could lead to any number of catastrophic outcomes.
In the specific case of generated code, formal verification provides mathematically rigorous guarantees on the correctness of code. What if there were a way to automatically apply formal verification to generated code? This would not only provide a scalable solution, but it could actually lead to a future in which generated code is more reliable than human-written code. Currently, formal verification is only possible with the aid of time-consuming human expertise. The main hypothesis of this work is that LLMs are well-positioned to generate the collateral needed to help formal verification succeed; furthermore, they can do this without compromising the formal guarantees provided by formal methods.
We name our approach Clover, short for Closed-loop Verifiable Code Generation, and we predict that Clover, coupled with steadily improving generative AI and formal tools, will enable a future in which fully automatic, scalable generation of formally verified code is feasible.
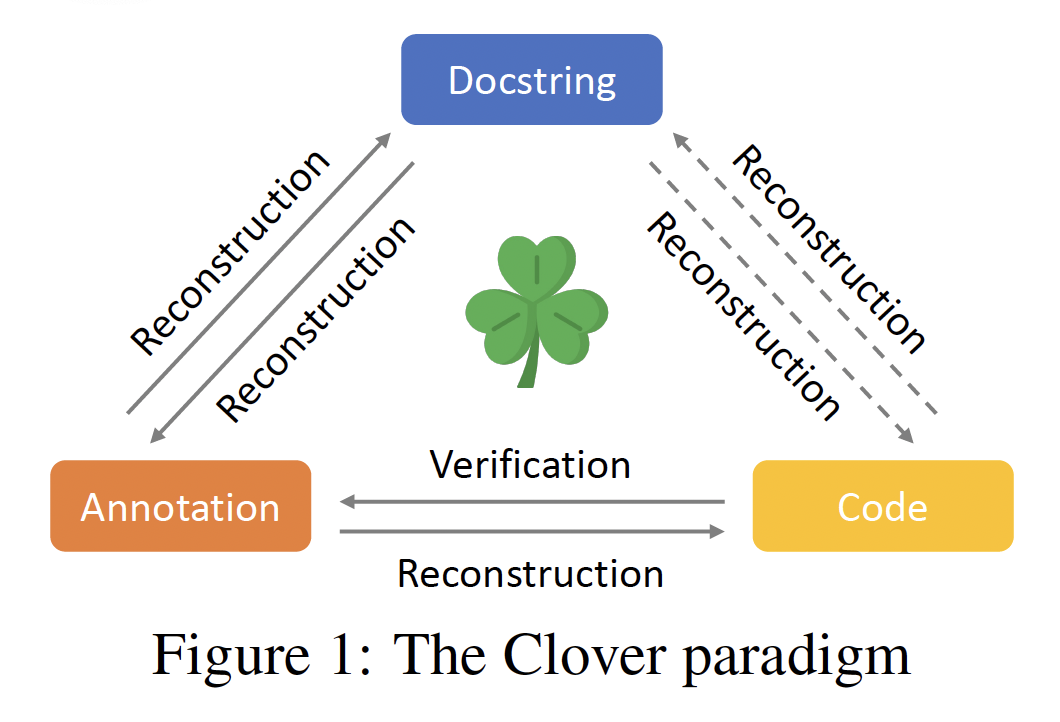
The Clover paradigm The Clover paradigm consists of two phases. In the first (generation) phase, some process is used to create code annotated with a formal specification and accompanied by a natural language documentation string. In the second (verification) phase, a series of consistency checks are applied to the code, annotations, and docstrings. The Clover hypothesis is that if the consistency checks pass, then (i) the code is functionally correct with respect to its annotation; (ii) the annotation captures the full functionality of the code; and (iii) the docstring also accurately reflects the functionality of the code (see Figure 1).
The idea is that we can unleash increasingly powerful and creative generative AI techniques in the generation phase, and then use the verification phase as a strong filter that only approves of code that is formally verified, accurately documented, and internally consistent.
Our contributions include:
- the Clover paradigm with a solution for the verification phase;
- the CloverBench dataset, featuring manually annotated Danfy programs with docstrings, which contains both ground-truth examples and incorrect examples;
- a feasibility demonstration of using GPT-4 to generate specifications;
Our initial experiments on CloverBench are promising. Our implementation accepts 87% of the correct examples and almost rejects 100% of the incorrect examples. We expect that the acceptance rate can be improved in a variety of ways while maintaining the strong ability to reject incorrect code.

Chuyue Sun (Livia) is a Ph.D. student at Stanford University's Computer Science Department advised by Professor Clark Barrett. She works on formal verification and large language models. She obtained a bachelor's degree from MIT. Her homepage is at https://web.stanford.edu/~chuyues/index.html
Ying Sheng is a Ph.D. candidate in Computer Science at Stanford University, advised by Clark Barrett. Her research focuses on building and deploying large language model applications, emphasizing accessibility, efficiency, programmability, and verifiability. Ying has authored numerous papers in top-tier AI, system, and automated reasoning conferences and journals, such as NeurIPS, ICML, ICLR, OSDI, SOSP, IJCAR, and JAR. Her work has received a Best Paper award (as first author) at IJCAR and a Best Tool Paper award at TACAS. As a core member of the LMSYS Org, she has developed influential open models, datasets, systems, and evaluation tools, such as Vicuna, Chatbot Arena, and SGLang. Ying is a recipient of the Machine Learning and Systems Rising Stars Award (2023) and the a16z Open Source AI Grant (2023). More information about her can be found at https://sites.google.com/view/yingsheng